Scala’s Collections notes
Scala 集合类系统地区分了可变的和不可变的集合。可变集合可以在适当的地方被更新或扩展。这意味着你可以修改,添加,移除一个集合的元素。
而不可变集合类,相比之下,永远不会改变。不过,你仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。
所有的集合类都可以在包scala.collection 或scala.collection.mutable,scala.collection.immutable,scala.collection.generic中找到。
默认情况下,Scala 一直采用不可变集合类。
Traversable类提供了所有集合支持的API,同时,对于特殊类型也是有意义的。
Collections: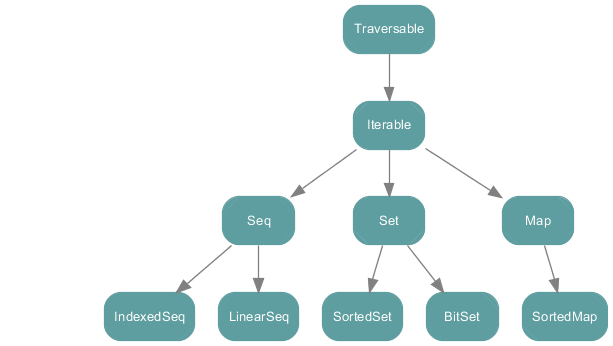
Collections.Immutable: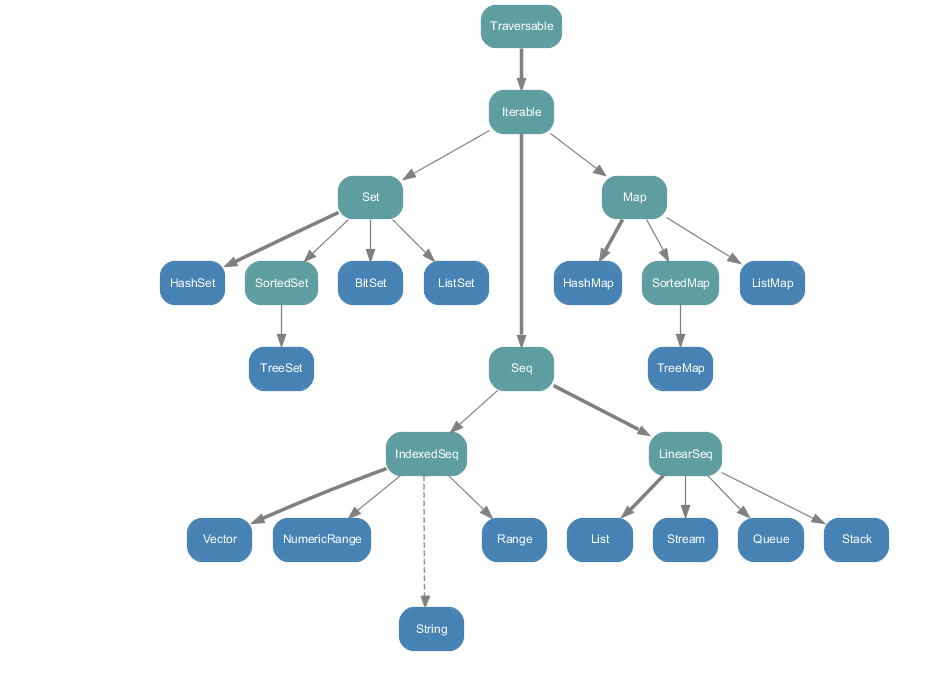
Collections.Mutable: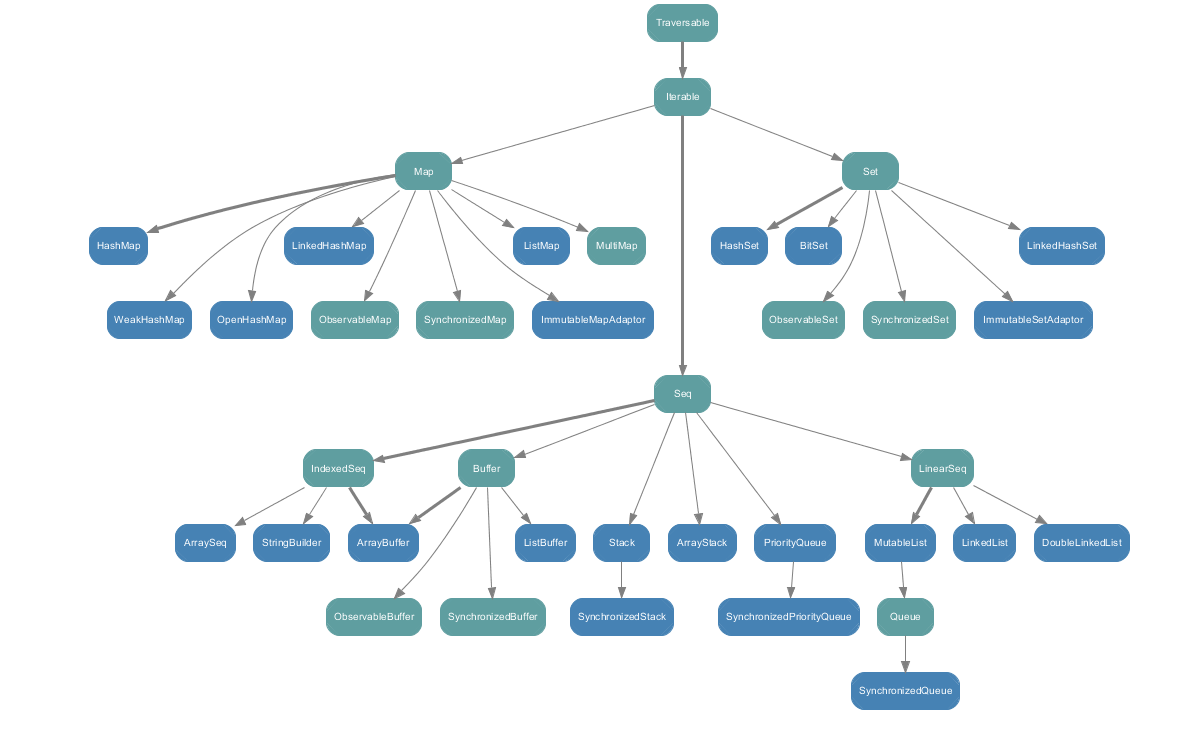
Trait Traversable
Traversable(遍历)是容器(collection)类的最高级别特性,它唯一的抽象操作是foreach.
需要实现Traversable的容器(collection)类仅仅需要定义与之相关的方法,其他所有方法可都可以从Traversable中继承。
Traversable同时定义的很多具体方法,如下表所示。这些方法可以划分为以下类别:
1, ++(addition
表示把两个traversable对象附加在一起或者把一个迭代器的所有元素添加到traversable对象的尾部。
2, Map操作
有map,flatMap和collect,它们可以通过对容器中的元素进行某些运算来生成一个新的容器。
3, 转换器(Conversion)
操作包括toArray,toList,toIterable,toSeq,toIndexedSeq,toStream,toSet,和toMap,它们可以按照某种特定的方法对一个Traversable 容器进行转换。等容器类型已经与所需类型相匹配的时候,所有这些转换器都会不加改变的返回该容器。例如,对一个list使用toList,返回的结果就是list本身。
4, 拷贝(Copying)
操作有copyToBuffer和copyToArray。从字面意思就可以知道,它们分别用于把容器中的元素元素拷贝到一个缓冲区或者数组里。
5, Size info
操作包括有isEmpty,nonEmpty,size和hasDefiniteSize。Traversable容器有有限和无限之分。比方说,自然数流Stream.from(0)就是一个无限的traversable 容器。hasDefiniteSize方法能够判断一个容器是否可能是无限的。若hasDefiniteSize返回值为ture,容器肯定有限。若返回值为false,根据完整信息才能判断容器(collection)是无限还是有限。
6, 元素检索(Element Retrieval)
操作有head,last,headOption,lastOption和find。这些操作可以查找容器的第一个元素或者最后一个元素,或者第一个符合某种条件的元素。注意,尽管如此,但也不是所有的容器都明确定义了什么是“第一个”或”最后一个“。例如,通过哈希值储存元素的哈希集合(hashSet),每次运行哈希值都会发生改变。在这种情况下,程序每次运行都可能会导致哈希集合的”第一个“元素发生变化。如果一个容器总是以相同的规则排列元素,那这个容器是有序的。大多数容器都是有序的,但有些不是(例如哈希集合)– 排序会造成一些额外消耗。排序对于重复性测试和辅助调试是不可或缺的。这就是为什么Scala容器中的所有容器类型都把有序作为可选项。例如,带有序性的HashSet就是LinkedHashSet。
7, 子容器检索(sub-collection Retrieval)
操作有tail,init,slice,take,drop,takeWhilte,dropWhile,filter,filteNot和withFilter。它们都可以通过范围索引或一些论断的判断返回某些子容器。
8, 拆分(Subdivision)
操作有splitAt,span,partition和groupBy,它们用于把一个容器(collection)里的元素分割成多个子容器。
9, 元素测试(Element test)
包括有exists,forall和count,它们可以用一个给定论断来对容器中的元素进行判断。
10, 折叠(Folds)
操作有foldLeft,foldRight,/:,:\,reduceLeft和reduceRight,用于对连续性元素的二进制操作。
11, 特殊折叠(Specific folds)
包括sum, product, min, max。它们主要用于特定类型的容器(数值或比较)。
12, 字符串(String)
操作有mkString,addString和stringPrefix,可以将一个容器通过可选的方式转换为字符串。
13, 视图(View)
操作包含两个view方法的重载体。一个view对象可以当作是一个容器客观地展示。接下来将会介绍更多有关视图内容。
Trait Iterable
许多Iterable 的子类覆写了Iteable的foreach标准实现,因为它们提供了更多有效的实现。记住,由于性能问题,foreach是Traversable所有操作能够实现的基础。 Iterable有两个方法返回迭代器:grouped和sliding。
Trait Iterable操作
抽象方法:
xs.iterator xs迭代器生成的每一个元素,以相同的顺序就像foreach一样遍历元素。其他迭代器:
xs grouped size 一个迭代器生成一个固定大小的容器(collection)块。
xs sliding size 一个迭代器生成一个固定大小的滑动窗口作为容器(collection)的元素。子容器(Subcollection):
xs takeRight n 一个容器(collection)由xs的最后n个元素组成(或,若定义的元素是无序,则由任意的n个元素组成)。
xs dropRight n 一个容器(collection)由除了xs 被取走的(执行过takeRight ()方法)n个元素外的其余元素组成。拉链方法(Zippers):
xs zip ys 把一对容器 xs和ys的包含的元素合成到一个iterabale。
xs zipAll (ys, x, y) 一对容器 xs 和ys的相应的元素合并到一个iterable ,实现方式是通过附加的元素x或y,把短的序列被延展到相对更长的一个上。
xs.zip WithIndex 把一对容器xs和它的序列,所包含的元素组成一个iterable 。比对:
xs sameElements ys 测试 xs 和 ys 是否以相同的顺序包含相同的元素。
在Iterable下的继承层次结构你会发现有三个traits:Seq,Set,和 Map。
序列trait:Seq、IndexedSeq及LinearSeq
Seq trait用于表示序列。所谓序列,指的是一类具有一定长度的可迭代访问的对象,其中每个元素均带有一个从0开始计数的固定索引位置。
序列的操作有以下几种,如下表所示:
- 索引和长度的操作
apply、isDefinedAt、length、indices,及lengthCompare。序列的apply操作用于索引访问;因此,Seq[T]类型的序列也是一个以单个Int(索引下标)为参数、返回值类型为T的偏函数。换言之,Seq[T]继承自Partial Function[Int, T]。序列各元素的索引下标从0开始计数,最大索引下标为序列长度减一。序列的length方法是collection的size方法的别名。lengthCompare方法可以比较两个序列的长度,即便其中一个序列长度无限也可以处理。 - 索引检索操作
(indexOf、lastIndexOf、indexofSlice、lastIndexOfSlice、indexWhere、lastIndexWhere、segmentLength、prefixLength)用于返回等于给定值或满足某个谓词的元素的索引。 - 加法运算
(+:,:+,padTo)用于在序列的前面或者后面添加一个元素并作为新序列返回。 - 更新操作
(updated,patch)用于替换原序列的某些元素并作为一个新序列返回。 - 排序操作
(sorted, sortWith, sortBy)根据不同的条件对序列元素进行排序。 - 反转操作
(reverse, reverseIterator, reverseMap)用于将序列中的元素以相反的顺序排列。 - 比较
(startsWith, endsWith, contains, containsSlice, corresponds)用于对两个序列进行比较,或者在序列中查找某个元素。 - 多集操作
(intersect, diff, union, distinct)用于对两个序列中的元素进行类似集合的操作,或者删除重复元素。
- 特性(trait) Seq 具有两个子特征(subtrait) LinearSeq和IndexedSeq。它们不添加任何新的操作,但都提供不同的性能特点:线性序列具有高效的 head 和 tail 操作,而索引序列具有高效的apply, length, 和 (如果可变) update操作。
常用线性序列有 scala.collection.immutable.List和scala.collection.immutable.Stream。常用索引序列有 scala.Array scala.collection.mutable.ArrayBuffer。
缓冲器
Buffers是可变序列一个重要的种类。它们不仅允许更新现有的元素,而且允许元素的插入、移除和在buffer尾部高效地添加新元素。buffer 支持的主要新方法有:用于在尾部添加元素的 += 和 ++=;用于在前方添加元素的+=: 和 ++=: ;用于插入元素的 insert和insertAll;以及用于删除元素的 remove 和 -=。
ListBuffer和ArrayBuffer是常用的buffer实现 。顾名思义,ListBuffer依赖列表(List),支持高效地将它的元素转换成列表。而ArrayBuffer依赖数组(Array),能快速地转换成数组。
集合Set
集合是不包含重复元素的可迭代对象。分为几类:
- 测试型的方法
contains,apply,subsetOf。contains 方法用于判断集合是否包含某元素。集合的 apply 方法和 contains 方法的作用相同,因此 set(elem) 等同于 set contains elem。这意味着集合对象的名字能作为其自身是否包含某元素的测试函数。 - 加法类型的方法
+和++。添加一个或多个元素到集合中,产生一个新的集合。 - 减法类型的方法
-、--。它们实现从一个集合中移除一个或多个元素,产生一个新的集合。
集合的两个特质是 SortedSet 和 BitSet。
有序集(SortedSet)
SortedSet 是指以特定的顺序(这一顺序可以在创建集合之初自由的选定)排列其元素(使用iterator或foreach)的集合。 SortedSet 的默认表示是有序二叉树,即左子树上的元素小于所有右子树上的元素。这样,一次简单的顺序遍历能按增序返回集合中的所有元素。Scala的类 immutable.TreeSet 使用红黑树实现,它在维护元素顺序的同时,也会保证二叉树的平衡,即叶节点的深度差最多为1。
位集合(Bitset)
位集合是由单字或多字的紧凑位实现的非负整数的集合。其内部使用 Long 型数组来表示。第一个 Long 元素表示的范围为0到63,第二个范围为64到127,以此类推
当位集合包含的元素值都比较小时,它比其他的集合类型更紧凑。位集合的另一个优点是它的 contains 方法(成员测试)、+= 运算(添加元素)、-= 运算(删除元素)都非常的高效。
映射
映射(Map)是一种可迭代的键值对结构(也称映射或关联)。Scala的Predef类提供了隐式转换,允许使用另一种语法:key -> value,来代替(key, value)。如:Map(“x” -> 24, “y” -> 25, “z” -> 26)等同于Map((“x”, 24), (“y”, 25), (“z”, 26)),却更易于阅读。
映射(Map)的基本操作与集合(Set)类似。下面的表格分类总结了这些操作:
- 查询类操作
apply、get、getOrElse、contains和DefinedAt。它们都是根据主键获取对应的值映射操作。例如:def get(key): Option[Value]。“m get key” 返回m中是否用包含了key值。如果包含了,则返回对应value的Some类型值。否则,返回None。这些映射中也包括了apply方法,该方法直接返回主键对应的值。apply方法不会对值进行Option封装。如果该主键不存在,则会抛出异常。 - 添加及更新类操作
+、++、updated,这些映射操作允许你添加一个新的绑定或更改现有的绑定。 - 删除类操作
-、–,从一个映射(Map)中移除一个绑定。 - 子集类操作
keys、keySet、keysIterator、values、valuesIterator,可以以不同形式返回映射的键和值。 - filterKeys、mapValues等变换用于对现有映射中的绑定进行过滤和变换,进而生成新的映射。
getOrElseUpdate特别适合用于访问用作缓存的映射(Map)。假设调用函数f开销巨大:1
2
3
4def f(x: String) = {
println("taking my time."); sleep(100)
x.reverse
}
此外,再假设f没有副作用,即反复以相同参数调用f,得到的结果都相同。那么,我们就可以将之前的调用参数和计算结果保存在一个映射(Map)内,今后仅在映射中查不到对应参数的情况下实际调用f,这样就可以节约时间。这个映射便可以认为是函数f的缓存。1
val cache = collection.mutable.Map[String, String]()
现在,我们可以写出一个更高效的带缓存的函数f:1
2def cachedF(s: String) = cache.getOrElseUpdate(s, f(s))
cachedF("abc")
稍等片刻。1
2
3res3: String = cba
scala> cachedF("abc")
res4: String = cba